
Table des matières de l'article :
Chaque webmaster sait qu'il y a certains aspects d'un site Web que vous ne voulez pas explorer ou indexer. Le fichier robots.txt vous donne la possibilité de spécifier ces sections et de les transmettre aux robots des moteurs de recherche. Dans cet article, nous montrerons les erreurs courantes qui peuvent survenir lors de la création d'un fichier robots.txt, comment les éviter et comment surveiller votre fichier robots.txt.
Il existe de nombreuses raisons pour lesquelles les opérateurs de sites Web peuvent vouloir exclure certaines parties d'un site Web de l'index des moteurs de recherche, par exemple si des pages sont masquées derrière un identifiant, sont archivées ou si vous souhaitez tester des pages d'un site Web avant qu'elles ne soient publiées. "Une norme pour l'exclusion des robots» A été publié en 1994 pour rendre cela possible. Ce protocole établit des directives selon lesquelles avant de commencer l'exploration, le robot d'exploration du moteur de recherche doit d'abord rechercher le fichier robots.txt dans le répertoire racine et lire les instructions dans le fichier.
De nombreuses erreurs possibles peuvent survenir lors de la création du fichier robots.txt, telles que des erreurs de syntaxe si une instruction n'est pas écrite correctement ou des erreurs résultant d'un verrouillage involontaire d'un répertoire.
Voici quelques-unes des erreurs robots.txt les plus courantes :
Erreur n.m. 1 : utilisation d'une syntaxe incorrecte
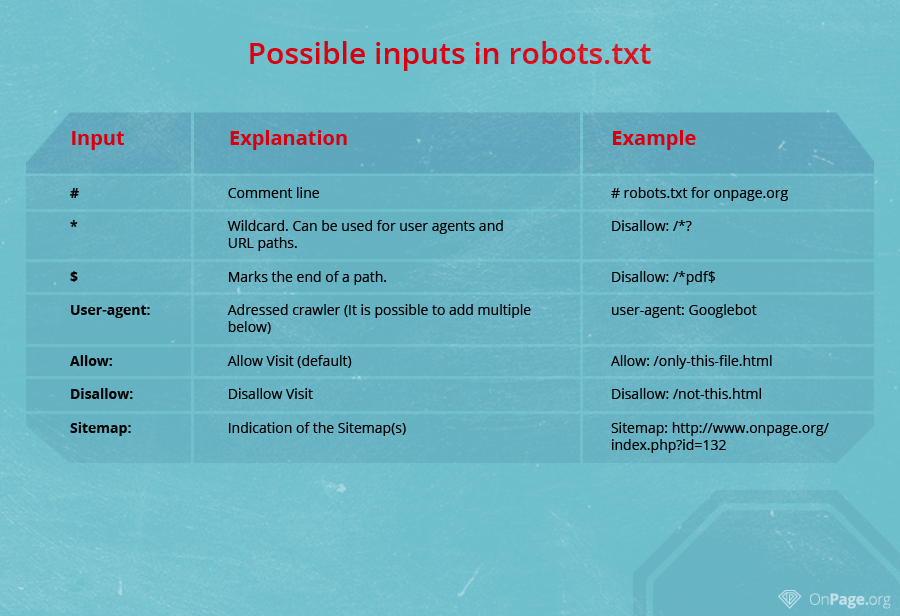
robots.txt est un simple fichier texte et peut facilement être créé à l'aide d'un éditeur de texte. Une entrée dans le fichier robots.txt est toujours composée de deux parties : la première partie spécifie l'interpréteur auquel appliquer l'instruction (par exemple Googlebot), et la deuxième partie contient des commandes, telles que "Disallow", et contient une liste de toutes les sous-pages qui n'ont pas besoin d'être numérisées. Pour que les instructions du fichier robots.txt prennent effet, la syntaxe correcte doit être utilisée comme indiqué ci-dessous.
Agent utilisateur : Googlebot Disallow : / example_directory /
Dans l'exemple ci-dessus, il est interdit au robot d'exploration de Google d'explorer le répertoire / example_directory /. Si vous souhaitez que cela s'applique à tous les robots d'exploration, vous devez utiliser le code suivant dans votre fichier robots.txt :
User-agent : * Disallow : / example_directory /
L'astérisque (également appelé caractère générique) agit comme une variable pour tous les robots. De même, vous pouvez utiliser un slash (/) pour éviter que l'ensemble du site soit indexé (par exemple, pour une version d'essai avant sa mise en ligne en production).
Agent utilisateur: * Interdire: /
Erreur n.m. 2 : bloquer les composants du chemin au lieu d'un répertoire (en oubliant "/")
Lorsque vous excluez un répertoire de l'exploration, n'oubliez pas d'ajouter la barre oblique au nom du répertoire. Par exemple,
Interdire : / répertoire non seulement les blocs /répertoire/, mais aussi /répertoire-un.html
Si vous souhaitez exclure plusieurs pages de l'indexation, vous devez ajouter chaque répertoire sur une ligne différente. L'ajout de plusieurs chemins dans la même ligne entraîne généralement des erreurs indésirables.
Agent utilisateur : googlebot Disallow : / example-directory / Disallow : / example-directory-2 / Disallow : / example-file.html
Erreur n.m. 3 : blocage involontaire des répertoires
Avant de télécharger le fichier robots.txt dans le répertoire racine du site Web, vous devez toujours vérifier si sa syntaxe est correcte. Même la plus petite erreur pourrait amener le robot à ignorer les instructions du fichier et à explorer des pages qui ne devraient pas être indexées. Assurez-vous toujours que les répertoires qui ne doivent pas être indexés sont répertoriés après la commande Interdire :.
Même dans les cas où la structure de la page de votre site Web change, par exemple en raison d'un restyle, vous devez toujours vérifier le fichier robots.txt pour les erreurs.
Erreur n.m. 4 - Le fichier robots.txt n'est pas enregistré dans le répertoire racine
L'erreur la plus courante associée au fichier robots.txt ne parvient pas à enregistrer le fichier dans le répertoire racine du site Web. Les sous-répertoires sont généralement ignorés car les agents utilisateurs ne recherchent que le fichier robots.txt dans le répertoire racine.
L'URL correcte du fichier robots.txt d'un site Web doit avoir le format suivant :
http://www.your-website.com/robots.txt
Erreur n.m. 5 : Ne pas autoriser les pages avec une redirection
Si les pages bloquées dans votre fichier robots.txt comportent des redirections vers d'autres pages, le robot d'exploration peut ne pas reconnaître les redirections. Dans le pire des cas, cela pourrait entraîner l'apparition de la page dans les résultats de recherche, mais avec une URL incorrecte. De plus, les données Google Analytics pour votre projet peuvent également être incorrectes.
Indice : robots.txt contre noindex
Il est important de noter que l'exclusion de pages dans le fichier robots.txt n'implique pas nécessairement que les pages ne sont pas indexées. Par exemple, si une URL explorée dans robots.txt est liée à une page externe. Le fichier robots.txt vous permet simplement de contrôler l'agent utilisateur. Cependant, ce qui suit apparaît souvent à la place de la description Meta car il est interdit au bot de crawler :
"Une description de ce résultat n'est pas disponible en raison du fichier robots.txt de ce site."

Figure 4: Exemple d'extrait d'une page bloquée utilisant le fichier robots.txt mais toujours indexé
Comme vous pouvez le voir, un seul lien sur la page respective suffit pour que la page soit indexée, même si l'URL est définie sur « Interdire » dans le fichier robots.txt. De même, l'utilisation de la balise cela peut, dans ce cas, ne pas empêcher l'indexation car le crawler n'a jamais pu lire cette partie du code en raison de la commande disallow dans le fichier robots.txt.
Pour empêcher certaines URL d'apparaître dans l'index Google, vous devez utiliser la balise , tout en permettant au robot d'exploration d'accéder à ce répertoire.
Conclusions
Nous avons vu et examiné très rapidement quelles sont les principales erreurs du fichier robots.txt qui dans certains cas peuvent considérablement compromettre la visibilité et le positionnement de votre site web, arrivant dans les cas les plus graves jusqu'à l'élimination totale de la SERP.
Si vous envisagez de ne pas avoir de tels problèmes avec le fichier robots.txt parce que vous savez comment cela fonctionne et que vous ne feriez jamais d'actions improvisées, sachez que parfois les erreurs dans le fichier robots.txt sont le résultat d'oublis dans le CMS configuration telle que WordPress ou même des attaques de logiciels malveillants ou des actions de sabotage visant à faire perdre à votre site son indexation et son classement.
Le meilleur conseil que nous puissions vous donner est de surveiller constamment le fichier robots.txt au moins une fois par semaine et de vérifier sa syntaxe correcte et son bon fonctionnement lorsque vous remarquez des signaux d'alarme tels qu'une baisse soudaine du trafic ou la présence de moteurs de recherche sur le SERP Recherche.